on
관계형 데이터 모델링 4
물리적 데이터 모델링
물리적 데이터 모델링
개요
논리적 데이터 모델링이 관계형 데이터베이스에 맞는 표를 만드는 것이라면 물리적 데이터 모델링에서는 구체적인 제품에 맞게 성능을 고려하여 현실적인 표로 만드는 것이다.
실제 프로그램을 만들었을 때, 정규화된 데이터베이스에서 문제가 생겨 속도가 느려질 수 있다. 그것을 고치기 위해 방법을 도입하거나 모델을 수정하는 등이 필요하다.
Index
행에 대한 읽기 성능을 향상 시키고 쓰기 성능을 저하 시키는 방법이다.
쓰기를 할 경우 입력된 정보를 알맞게 정리하는데 많은 시간을 소모한다. 또한, 저장공간을 많이 차지할 수 있다.
하지만, 읽기 속도가 매우 향상되기 때문에 사용 가능하다.
application
입력에 대한 실행 결과를 미리 저장해놓는 cache와 같은 방법을 통해 Database의 부하를 줄이는 방법도 가능하다.
역정규화 (Denormalization)
정규화를 통해 만든 이상적인 표를 구조를 변경하는 방법이다.
정규화는 대체로 쓰기의 편리함을 위해 읽기의 성능을 희생하는 방법이다. 읽기를 위해서는 Join을 활용해야 하는데 이때, 많은 시간이 소모된다.
다른 방법을 시도해보고 마지막 수단으로 사용하는 것이 바람직하다.
역정규화에 해당하는 방법은 다음과 같을 수 있다.
- Column의 역정규화
- Column 중복 : JOIN을 줄이기
역정규화 전
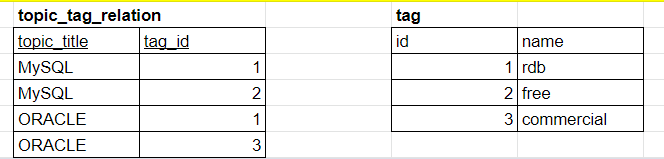
topic_title로 tag_name을 구하는 요청이 많은 상황을 가정하면, JOIN을 사용할 때, 많은 시간이 소모되어 성능이 저하될 우려가 있다.
역정규화 후
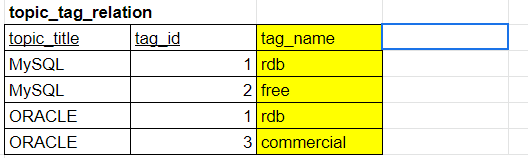
중복을 허용하는 대신 topic_title에 대한 tag_name을 한번에 알 수 있게 되었다.
-
파생 Column의 형성 : 계산 작업을 줄이기
역정규화 전

author가 작성한 topic의 수를 기능을 요청하는 경우가 많은 경우
역정규화 후
!
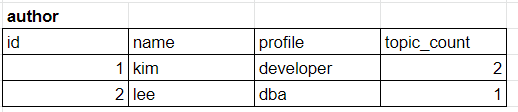
각각의 저자가 몇 개의 글을 작성했는지 목록으로 표현함으로서 계산 작업을 줄일 수 있다.
-
테이블의 역정규화
주로 여러 대의 서버를 활용할 수 있을 때 사용한다.
- Column을 기준으로 테이블을 분리 (Database Sharding)
역정규화 전
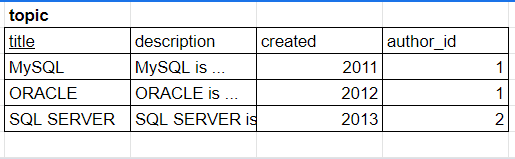
description Column은 가지고 있는 데이터의 크기가 크다.
역정규화 후

용량이 많은 Column이 호출 횟수가 적다면 따로 Table를 분리함으로서 다른 Column을 호출할 때 속도를 향상 시킬 수 있다.
- Row를 기준으로 테이블을 분리
역정규화 전
topic Table의 행의 크기가 너무 큰 경우
역정규화 후

행을 기준으로 Table을 나눔으로서 호출할 때 속도를 향상 시킬 수 있다.
-
관계의 역정규화
FK(Foreign Key)를 추가함으로서 JOIN을 줄인다.
역정규화 전

topic title에 해당하는 author_id의 topic_id를 얻기 위해서는 다수의 JOIN을 사용해야 한다.
역정규화 후
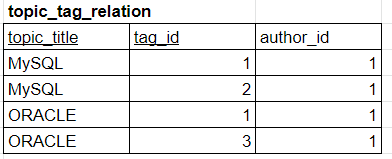
Colomn을 추가함으로서 JOIN을 줄일 수 있다.
Discussion and feedback